ML pipeline
This page contains a quick overview of the machine learning pipeline along with how it would interact with society.
Under Construction
This page is still under construction. In particular, nothing here is final while this sign still remains here.
A Request
I know I am biased in favor of references that appear in the computer science literature. If you think I am missing a relevant reference (outside or even within CS), please email it to me.
The ML pipeline
Recall the overview of supervised learning that we saw in the introduction. The main idea there was we start off with some data and then we learn a model (the function $f$ that we saw earlier). Then later on we use the model of classify new inputs/images. This while process can be abstracted out as a machine learning pipeline:

Some caveats
While the figure suggests a sequential process, it by no means is sequential. In particular, it is common to have "backwards arrows" because e.g. while training a model, we might realize that we need more data and that would mean we need to go back to the data collection stage. We do not explicitly show the backwards arrows to make the figures (especially the ones that will follow) less cluttered. However, in your mind you should always have the backwards arrows in.
Clearly, we are not the first to come up with such a pipeline. At this point of time, this is fairly standard. See e.g. the data science cycle that this Berkeley data science page presents a similar pipeline (though with more details and with an explicit cycle to present the missing backward edges we mentioned above.
An example
Just to make sure the ML pipeline above makes sense, let us instantiate the above framework with the specific cats vs. dogs example we did in the introduction:

A Reminder
A gentle reminder that the "instantiations" of various stages of the ML pipeline are made up (in particular the function $f$ as well as the labeled data are all made up and not from any real system). Later on in the course, we will see actual instantiations of these steps on real labeled data where you will run actual code to generate the model $f$.
For now bear with us and let us walk through the above instantiation in text below.
Below we walk through the five stages in the abstract ML pipeline with the the specific cats vs. dogs example we did in the introduction:
Start with a question: In our case the question was to classify any given image as acator adog.Collect data: In our case this was the "database" of labeledcatanddogpictures that we assumed exists.Train model: This step we really waved our hands here and assumed that "somehow" we came up with a model $f$. Later on in the course, we will see specific ways in which this step can be implemented.Evaluate model: Again we did not specific how we did this but if one is willing to accept a magical $f$ as in the example above exists, then this step was easy-- the function $f$ had no error on the labeled data it was trained on.Deploy!: This is when we "ran" $f$ onWarren's picture and determined that the (completely made up and non-existent) $f$ correctly identified the image as adog.
What is missing?
The pipeline above actually is how many computer scientists think of how ML works and while it is a nice abstraction (and we will see a more refined pipeline shortly) it is leaving out a lot of context in which these pipeline operate-- recall all of notions of biased algorithms that we saw in the introduction. The missing ingredient is the society!, which potentially affects all the stages of the ML pipeline. In other words, the more appropriate way to look at the ML pipeline is as follows:

Wait, there is more!
It turns out that while the picture above is a decent overview to keep in mind, for this course, we will have a more detailed ML pipeline.
Forget about the society for a bit!
For a bit let us pretend to be cocooned computer scientists and let us look at the ML pipeline without bringing society into the mix. Do not worry, society will be back pretty soon!
We begin by re-drawing the basic ML pipeline that we seen so far with each box being colored with a different color (this will help us see how each of the boxes get broken up in the more detailed ML pipeline):

The following pipeline breaks up the above basic ML pipeline into smaller sub-tasks and gives rise to a more detailed ML pipeline (the sub-tasks below corresponding to each of the task above have the same color (though with differing opacity):

What do the terms above mean?
We have purposefully refrained from defining each of the boxes above. For now it is enough to realize that each sub-task of the same color in the new pipeline corresponds to the earlier task of the same color. We will give more details on each step when we do more walkthroughs.
Acknowledgments
The above ML pipeline is due to Hal Duame III . In particular, the above flowchart is basically the same as the one in his blog post on the machine learning pipeline . We have also used the same name for most of the tasks in the pipeline as in the blog post.
The post is specifically about debugging an ML pipeline but it is a great post on the ML pipeline itself (h/t to Suresh for pointing this out .
We will see instantiation of the above ML pipeline for some specific problems in the next few lectures but for the time being, we highly recommend reading through the blog post , which has an excellent running example of online ad display.
Putting society back in
Now if we put back the society into the picture, we get the framework that we will follow for the rest of the course:

The caveats again
As mentioned earlier, the "backwards arrows" have been left out for clarity in the framework above. Also, we again do not make any claim on the above framework being new.
In particular, after we wrote the first draft of these notes, we discovered a Medium article titled Black-Boxed Politics: Opacity is a Choice in AI Systems by Agata Foryciarz , Daniel Leufer and Katarzyna Szymielewicz . The article's main point is on the notion of "Explainable AI"-- something we will consider later in the course. However, as part of the article, they do have a framework similar to the one above (though with fewer technical steps but explicitly shows the cyclicity of the whole process and explicitly shows the stakeholders as well)
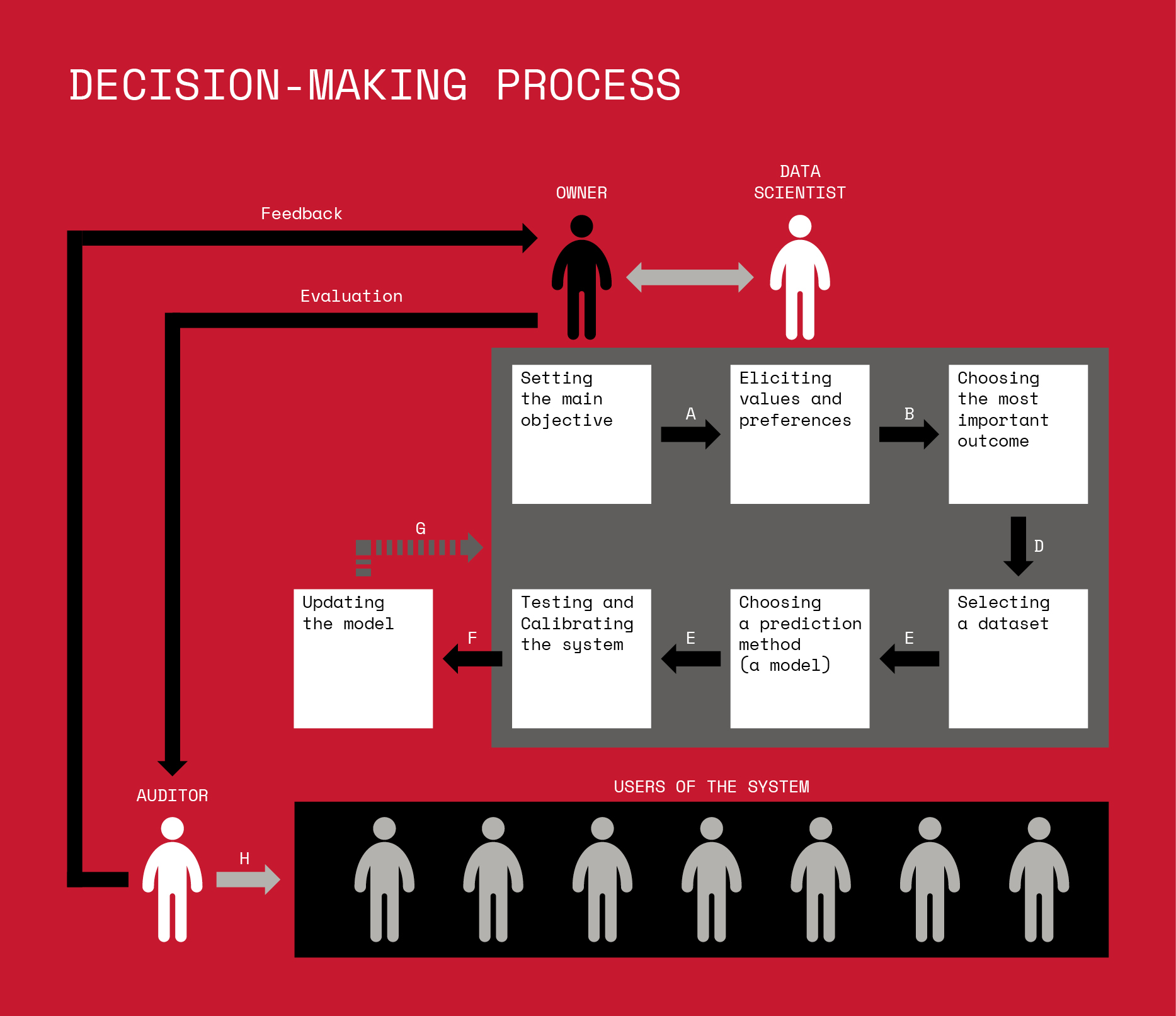
In addition, the article presents a great walkthrough of the above framework in the context of a hospital selecting patients to be enrolled in new program:

Rest of the course
Here is how the rest of the course if roughly going to look like:
- For the (roughly) first quarter of the course we will focus on the various tasks in the framework above (without the society in the picture). In this part of the course, the goal is to get enough technical details of the ML pipeline so that one can appreciate the latter part of the course better.
- For the remaining (roughly) three-quarters of the course we will focus on the red arrows in the picture above. We will begin this journey by ignoring most of the red arrows and come up with technical solutions to achieve (some notion of) fairness. We will then take a more holistic view of the framework and dive deeper into the (many!) issues that at this point are just represented as a single red arrow.
Next Up
Next, we will do a walkthrough of the ML pipeline.