Taking society into account
This page will start looking into the connections of society to the ML pipeline in a more systematic way.
-
Needless to say, the point distribution in the example below if not meant to be representative of any real-life data distribution. The setup is made to illustrate the point that will be made soon.
Under Construction
This page is still under construction. In particular, nothing here is final while this sign still remains here.
A Request
I know I am biased in favor of references that appear in the computer science literature. If you think I am missing a relevant reference (outside or even within CS), please email it to me.
Outline
Recall that we had stated with ML pipeline interacting with society, like so:

Over the various lectures, we have looked at these connections, though for the most part we have focused on the ML pipeline itself. The first time we specifically started looking at issues at the intersection of society and the ML pipeline was when we talked about fairness. Even then the focus was more on technical definitions of fairness and their connection to the ML pipeline (especially the definition of accuracy).
These notes mark the shift of the focus of the course from the ML pipeline to primarily considering how the society interacts with the ML pipeline. Specifically these notes will expand on the notions of bias we touched upon briefly and how it interacts with the ML pipeline in specific points. We will then consider the ML pipeline in the greater context of a sociotechnical system . In the remaining notes, we will consider specific parts of this sociotechnical systems (and some requirements that are would be placed by society on the ML pipeline in an ideal world).
The many forms of bias
Acknowledgments
This section borrows very heavily from a 2019 paper by Suresh and Guttag.
Different kinds of bias
As noted above, we have touched upon some notions of bias earlier, which for the sake of completeness we repeat below.
Another loaded term that we will use is the term bias. In particular, there are roughly three kinds of notions of bias that is relevant to these notes:
- The first notion (which might be the least known) occurs in a dataset where there are certain specific collection of input variable values occur more than others. This essentially measure how far away from a truly random dataset the given dataset is. Note that this notion is bias is necessary for ML to work. If all the datapoints are completely random (i.e. both their input and target variable values are completely random), then there is no bias for a classifier to "exploit"-- in other words, one might as well just output a random label for prediction.
- The second notion of bias is that of statistical bias , where in our setting this would mean that the binary classifier outcome does not reflect the distribution of the underlying target variable. Such a classifier would be well calibrated , if this does not happen. One could consider a well-calibrated binary classifier to be fair in some sense. This will be one notion of fairness that will come up in the COMPAS story. (This is the notion of fairness used in the rejoinder to the ProPublica article).
- The finally notion of bias is the colloquial use of the term that is meant to denote an outcome that is not fair. Most of the definitions of fairness in the literature deal with this notion of bias. And a couple of definition of this kind of fairness will also play a part in the COMPAS story (this is the notion of fairness used in the ProPublica article).
We have some time talking about the first two notions of bias above but we have been a bit hand-wavy with the third notion of bias. In this section,
Expanding on the colloquial use of bias
We will categorize these colloquial uses of bias into six categories (as advocated by Suresh and Guttag. We will, as promised, also see how these notions interact with the pipeline.
In the rest of the section, we will consider six classes of biases: Historical Bias, Representation Bias, Measurement Bias, Aggregation Bias, Evaluation Bias and Deployment Bias.
Historical Bias
We begin our discussion with the bias that already exists in society (independent of the ML pipeline). In particular, this is the bias that would persist in our training data even if we are able to perfectly sample from the existing population. This bias is termed as historical bias.
As in any society, US has its fair share of historical biases. Below is one example related to the notion of redlining (the video below talks about the origin of redlining and other related issues):
So for example if you just took a truly random sample of rich people, it will be biased towards whites and this is because of historical bias.
Another example that we have seen in the first set of notes is when one searches for the word ceo in Google Images, one gets a result like this:

As we had discussed earlier, the paucity of women CEO images could be attributed to the fact that in real life, there are not that many women CEOs: as of the writing of the notes less than $70\%$ of Fortune 500 companies had women CEOs --
Another example
While housing segregation has garnered attention, I personally had not thought about its relation to segregation at work and this video was quite interesting:
Coming back to the ML pipeline
Where in the ML pipeline does historical bias come into play?
As is evident from the discussion above, historical bias is present in society and whenever we collect data from society, historical bias comes into play. In other words, the interactions of society with the ML pipeline that are relevant to the ML pipeline are highlighted in this figure (the interactions that are not so relevant have been faded out):

Note that there is a "self-loop" in the society because historical bias tends to perpetuate (and this would happen even in the absence of the ML pipeline).
How we handle historical bias in the ML pipeline?
Among the five classes of bias we are going to study in these notes, historical bias is something that the ML pipeline has least control over. However, this does not mean that you as a developer of the ML pipeline should just raise your hands and "give up". At the very least you should be aware of historical bias so that you can make sure that the latter stages of the ML pipeline do not exacerbate the historical bias when you deploy your ML pipeline.
In certain situations, your real-life goal means you will have to account for historical bias. E.g. if the real life goal is to improve diversity in your company workforce, then if you are designing an ML pipeline to hire more diverse folks who will be successful in your company, then historical bias in your workforce (e.g. technology companies having much fewer women and even fewer people of color) is something that your ML pipeline will have to explicitly handle.
Automated hiring
ML pipeline are being deployed for hiring in many places. This is a pipeline where you should pay attention to historical biases in the data that you are using to figure out who would make for a "good" employee.
To get a sense of what can happen/go wrong: play this online game: Survival of the best fit .
Representation Bias
We now consider the notion of representation bias, which basically means that certain groups of people might be under-represented in the (training) dataset. Before moving on to two reasons why there might be representation bias, we compare this notion with the well-established notion of selection bias .
Relation to selection bias
Statistical bias refers to the issue that the your (training) dataset is not a perfectly random sample from the ground truth. I.e., the dataset point are not representative of the underlying population distribution. Thus, selection bias by definition leads to representative bias.
However, it is possible that there is representative bias even in the absence of selection bias. We will see a particular reason later on but here is another scenario. Consider the demographics of Finland , where non-whites form a tiny fraction of the Finnish population. Now if even if we had a truly random sample of the population of Finland, unless the sample size if very large, there will be very few non-whites in your sample. In other words, even though technically there is no selection bias, there will be representation bias in your system.
Next, let us look at two possible causes of representation bias.
Sampling/data collection method excludes certain part of the population
If your data collection mechanism does reach certain parts of the underlying population then the collected (training) data will have representation bias. We have looked at this before when we considered the "smartphone trap."
Recall the example of Street Bump :
Recall that idea behind Street bump is to collect data from volunteers' smartphones while they drive on the road condition and then potentially give information to municipalities to improve road conditions.
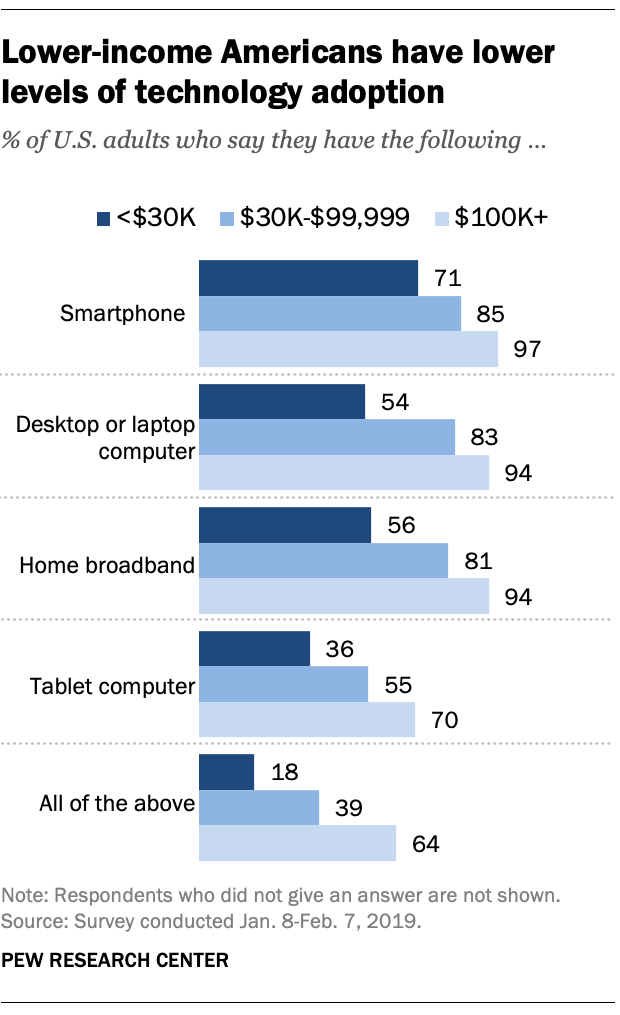
As we have seen before, the issue with the strategy to collect data from smartphones is that it excludes people who do not have smartphones. In particular, this excludes more poor people. According to this Pew Research article , 29% of Americans household incomes of below $30K do not have smartphones:
The training dataset population does not match the deployed population
The second reason representation bias can happen is because the training data that is used during model training phase might be different from the population on which the ML pipeline is deployed. This in turn could be due to at least two reasons. First, is the notion of concept drift where e.g. the underlying population itself might have changed. So if your training dataset is based on the older data then this issue will arise. The second possibility is that the training dataset could be representative of a certain segment of the population and not others. So if your model is trained on a certain segment of society, then it will probably not work well on another segment of society.
Here is one specific illustration of the second phenomenon in a more "physical" setting where the setting of the light sensor in automatic soap dispenser is tailored towards light-skinned people and does not work well for those with darker skins:
If you have ever had a problem grasping the importance of diversity in tech and its impact on society, watch this video pic.twitter.com/ZJ1Je1C4NW
— Chukwuemeka Afigbo (@nke_ise) August 16, 2017
We should note that this is not a recent phenomenon. For example, in the olden days, pictures had to be taken on physical "camera rolls." Since I am not sure how many of y'all actually know what a camera roll is, here is a preview:
In any case, film rolls where the way to take pictures before the advent of handheld devices that could take pictures. And they were originally developed for people with lighter skins (the video makes an interesting comment on some of the business reasons why this was changed):
Another example: ImageNet
Another example of this issue is the ImageNet data that has a lot of representation bias. For example, only $1\%$ and $2.1\%$ of the images come from China and India respectively (while they account for $36\%$ of the world population , which clearly is a case of selection bias (and hence representation bias). Here is a talk on an attempt to construct fairer datasets (and the first few minutes walks through various representation biases in ImageNet):
Coming back to the ML pipeline
Where in the ML pipeline does representation bias come into play?
In the discussion above, we considered two mechanisms by which representation bias can creep in. The first is how we decide to collect data (e.g. by using smartphones to collect data), which corresponds to the interaction between the data collection mechanism with the society. The second is potentially using an older dataset, which corresponds to the interaction between which data to collect? and society. Further, representation bias can also creep in when we are choosing the training dataset.
In other words, the interactions of society with the ML pipeline that are relevant to the ML pipeline are highlighted in this figure (the interactions that are not so relevant have been faded out):

How we handle representation bias in the ML pipeline?
Unlike the case of handling historical bias, handling representation bias is something that should be handled in the ML pipeline because one potentially could have more control over this kind of bias than historical bias.
If when creating the ML pipeline, you have control over the data collection mechanism, then you should make an effort to not create representation bias. However, we should note that this could be expensive. See e.g. this video that talks about this issue with the census (along with other issues):
If your ML pipeline uses an existing dataset then you should understand the history of the dataset. It would be helpful if the dataset has a datasheet associated with it.
Measurement Bias
Measurement bias, simply put, is the values/variables represented in the data not being exactly what we wanted to measure. In particular, this is related to the fact that we measure proxies instead of measuring the exact variable we want (because e.g. we cannot measure what we want to). We have seen this e.g. when we discussed who we use rearrest as a proxy for reoffend. And while we have talked about proxy variables in the context of the target variable the same thing can happen for input variables as well.
If we were actually measuring the actual variable that we are interested in (but if some error), then taking enough samples can potentially alleviate the problem. However, we often pick proxy variables which might be fundamentally different than the variable we are actually interested in and this can lead to measurement bias. Next we list three potential ways in which one can lead to measurement bias.
Prevalence of proxy variables varies across groups
For a given proxy variable (e.g. prior arrests and friend/family arrests, which are two input variables used by the COMPAS tool in computing its risk scores), different groups might have different amounts of data/rate of prevalence. Again, as was the case with rearrests vs reoffense, prior arrest is a proxy for prior criminal behavior but does not actually capture the latter. Since incarceration dis-proportionally impacts black males in the US, this would mean that using prior arrest record or friend/family arrests would be biased against black males:
As another example in a medical domain, if one is using "diagnosed with condition $X$" as a proxy for "has condition $X$" then this would lead to measurement bias since for example, it is known that gender can have an affect on diagnosis:
Proxy variable is an oversimplification
This is related to the notion of convenience trap that we have already seen. We pick a proxy variable since it is easier to measure but in reality is a gross oversimplification of the actual property we want to measure. For example, say we want to measure the likelihood that a recent graduate would succeed in a job/graduate school/life. This clearly is not something that can be easily measured (if at all) so one common proxy is to look at the GPA of the student. However, GPA is not a real good proxy for success in life later on:
Example: Predictive policing
As we have already seen multiple times, predicting when someone might commit a crime is riddled with potential biases. So far we have concentrated on COMPAS but there are many other tools out there:
We will not go through the various potential biases in predictive policing but will defer this example for a later exercise.
Coming back to the ML pipeline
Where in the ML pipeline does measurement bias come into play?
The main reason behind measurement bias is the use of proxy variables. This is definitely an issue in the learning problem step of the ML pipeline (which is where we determine the target variable). The data collection steps are also relevant since this is where we decide on the input variables (in particular, deciding what proxies we pick for input variables).
In other words, the interactions of society with the ML pipeline that are relevant to the ML pipeline are highlighted in this figure (the interactions that are not so relevant have been faded out):

How we handle measurement bias in the ML pipeline?
Unlike the case of handling historical bias and (to a lesser extent) handling representation bias, handling measurement bias is something that has to be handled in the ML pipeline since picking the proxy variables is fair and square part of the ML pipeline.
When picking the target and input variables, you should first check if any of the picked variables is a proxy for the actual variable you are trying to measure. If so, you should re-think your variable choice. Perhaps another variable is closer to the actual quantity you are trying to measure? If you cannot think of a better alternative you should be cognizant of the measurement bias you are introducing and at the very least this downside of the ML pipeline should be made clear to the actual users of the pipeline.
Aggregation Bias
Note that so far what we have done in the ML pipeline is to ask for a single model that we can use for prediction. However, this can problematic where the distribution of occurrence of the target variables differs across various groups. For example, the prevalence of diabetes differ (fairly substantially) across racial groups:
Aggregation bias occurs when we insist on one single model that has to work across various groups, which leads to sub-optimal prediction either for a single group or across multiple groups. To see this in action, consider the following situation (where for illustration purposes the $w$ group is boxed in with a gray boundary and the $b$ group is boxed in with a black boundary and recall that green triangles and red circles are positive and negative points in the underlying data while blue and yellow refer to the points that the model labels as positive and negatively respectively):1

Now it is easy to see that there is a simple decision tree model that fits this dataset perfectly:

However, suppose we have decided on a linear model (say for its explainability) as our model of choice. However, it is not hard to see that even the best linear model will have misclassifications in at least one group:

Of course the above is a simplified example (where one could argue that the decision tree that perfectly explains the dataset is also pretty explainable and the issue was more in our choice of choosing a linear model (more on this in a bit). However, as one can imagine the situation gets more complex for more general datasets. See e.g. the work of Dwork, Immorlica, Kalai and Leiserson in the 2018 FAT* conference for more on this.
Coming back to the ML pipeline
Where in the ML pipeline does aggregation bias come into play?
The main reason behind aggregation bias is the use of a single model, where instead of using different models for different groups would be better. This is definitely an issue in the target class/model step of the ML pipeline.
In other words, the interactions of society with the ML pipeline that are relevant to the ML pipeline are highlighted in this figure (the interactions that are not so relevant have been faded out):

How we handle aggregation bias in the ML pipeline?
Since aggregation bias is completely an artifact of the ML pipeline, this needs to be fixed/avoided when you are building an ML pipeline. One way to fix this is to learn different models for different groups in the underlying population. See the work of Dwork et al. for more references and pointers.
Evaluation Bias
As the name suggests, evaluation bias is bias that is introduced when (or more appropriately how) we evaluate our model. Recall that there are two steps in the ML pipeline corresponding to the evaluation of the model that we get from the model training steps: predicting on test data and then evaluating the error. And as we'll see shortly both of these steps can lead to bias.
Bias in testing dataset
As we have seen in historical bias, representation bias and measurement bias our training dataset can have biases in them. Now if we carve out our testing dataset from the dataset we collected earlier in the pipeline then there will be historical bias, representation bias and measurement bias in the testing dataset as well. For the rest of this section, we will consider another source of bias that is perhaps more germane to the testing dataset.
If you have designed an ML pipeline to improve say the accuracy of ML systems to solve a well-studied problem (e.g. image processing), then you will like to evaluate your model on a standard test dataset, which are called benchmarks (e.g. ImageNet ). The reason a benchmark is used to evaluate an ML pipeline (and computing systems in general) is because it makes it easier to compare two ML pipelines: if your ML pipeline say has a better accuracy on ImageNet than an existing ML pipeline to solve image classification, then you new ML pipeline is a "better" image classifier.
Unfortunately, this gives an incentive to the designer of an ML pipeline to build a model that is designed to work well on the benchmarks. The situation is somewhat similar to the notion of teaching to the test in relation to standardized test in US schools. In case you did not encounter standardized tests when you did your schooling, here is an overview:
In other words, the ML pipeline may be designed in such a way that actual parts of the testing dataset are taken directly from the testing dataset. If you think this is "cheating" then you would be right. Most of such cases have turned up in "ML competitions" where various ML models are submitted and there is a winner declared at the end (many times with cash reward).
ML competitions
The first example was dubbed as the first machine learning cheating scandal. ImageNet used to host an annual visual recognition challenge and we want to focus on the 2015 version of the challenge called ILSVRC . In order to help various teams make progress, any registered team could submit their model and see how well it was doing on the evaluation dataset (which was kept hidden). To avoid "teaching to the test scenario" each team was allowed up to two submissions per week. However, a team from Baidu was caught circumventing this rule , where the team did multiple submissions by using multiple ImageNet accounts. This MIT Tech Review article has more on this .
The second example of cheating on Kaggle competitions . In particular, the winning team for a pet agency adoption contest basically figured out the testing dataset and used it to train its model .
Using one notion of accuracy can lead to bias
We have alluded to this before: using one accuracy number to evaluate a model can hide bias. For example, consider the case where the population can be divided into two groups: group $b$ that constitutes $5\%$ of the population and the group $w$ that is $95\%$ of the population (so something like the case in Finland). Then we would have a model that works perfectly for group $w$ but is always incorrect for group $b$. Then the model has an overall accuracy of $95\%$, though it has $0\%$ accuracy for the $b$ group, which clearly is a biased outcome.
While the above example has the numbers "cooked up" to illustrate the difference, the overall situation is not far-fetched. In fact, we have already seen before, a similar situation has been observed in the context of facial recognition in the Gender Shades work:
Coming back to the ML pipeline
Where in the ML pipeline does evaluation bias come into play?
As was alluded to earlier in the section, evaluation bias is most applicable to the predict on test data and evaluate error steps of the ML pipeline.
In other words, the interactions of society with the ML pipeline that are relevant to the ML pipeline are highlighted in this figure (the interactions that are not so relevant have been faded out):

How we handle evaluation bias in the ML pipeline?
Since evaluation bias is pretty much an artifact of the ML pipeline, this needs to be fixed/avoided when you are building an ML pipeline. In fact, the ways to avoid evaluation bias follows from the two sources. First, at the very least, make sure that the training dataset is picked to be separate to the testing dataset. Second, be careful about which accuracy measure you pick to evaluate the error in the model: in particular, perhaps it makes sense to evaluate based on more than one measure, especially with respect to protected groups in your population.
Deployment Bias
Deployment bias arises when the (potentially implicit) assumption made about society when creating the ML pipeline are not true. Or put differently, the ML pipeline when deployed in real life is used in a way that was not taken into consideration. One recent-ish example is that of the Tay chatbot :
Here is a talk with bunch of other examples (though those examples comes in the later half):
Though there can be multiple reasons for deployment bias to be present, perhaps the main reason is that the ML pipeline is generally developed in "vacuum"-- i.e. as a standalone system without taking into account its interaction with society. As we will see shortly there are many such "traps" that an ML pipeline designer should avoid.
Coming back to the ML pipeline
Where in the ML pipeline does deployment bias come into play?
Deployment bias is by definition applicable to the deploy step of the ML pipeline.
In other words, the interactions of society with the ML pipeline that are relevant to the ML pipeline are highlighted in this figure (the interactions that are not so relevant have been faded out):

How we handle deployment bias in the ML pipeline?
The deployment bias by its definition cannot be handled just within the ML pipeline since the the issue crops up because of the interaction of society with the ML pipeline. We refer the reader to the 2019 FAT* paper by Selbst, boyd, Friedler, Venkatasubramanian and Vertesi, which talk about various "traps" that an ML pipeline designer should avoid (and some preliminary suggestions on how to try and avoid them). Many of the biases we have covered in these notes (not surprisingly) also make an appearance there.
Recap and an example
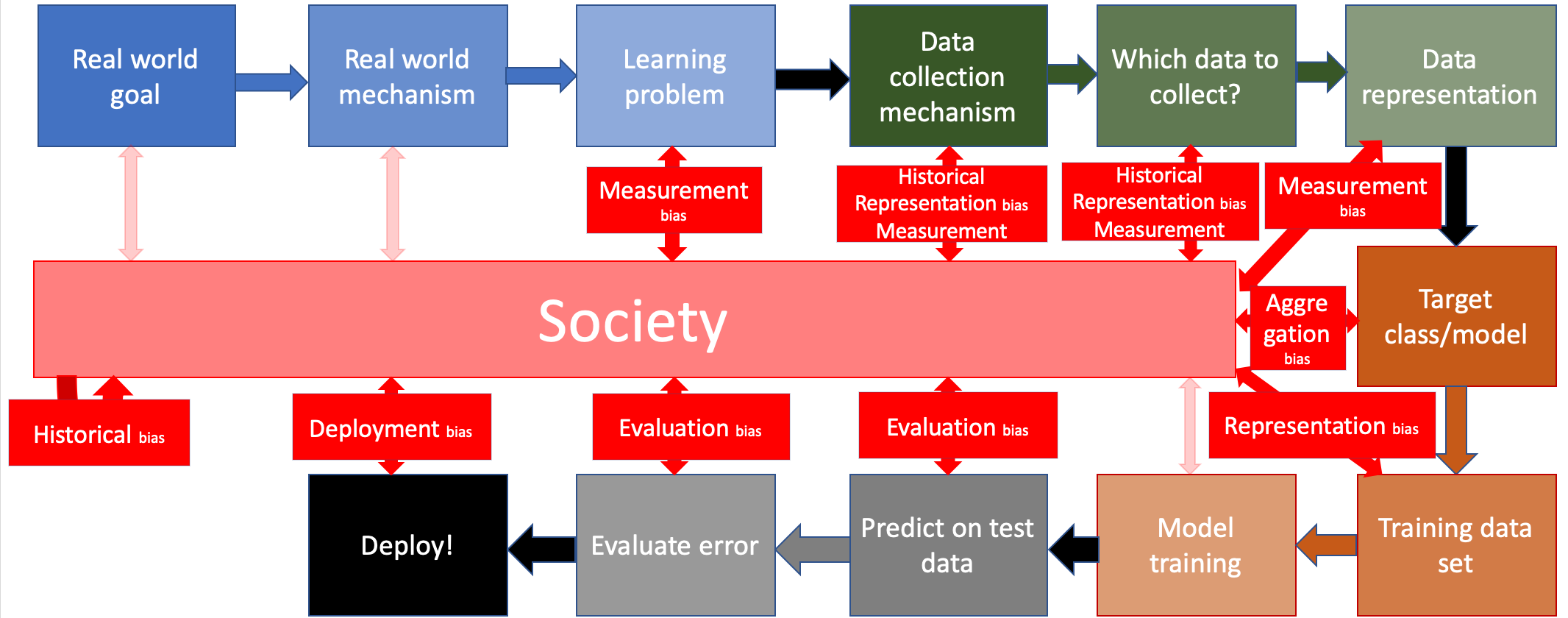
Let us now recollect all the kinds of biases we have seen in these notes and which parts of the ML pipeline they affect:
We conclude with couple of activities/exercises:
Exercise
First watch this video on potential issues with using ML in predictive policing:
What biases were identified in the above video? Is there some other notion of bias that we have seen in these notes that are relevant to predictive policing and are not mentioned in the video above?
Exercise
We did not hit all the interactions between the steps of the ML pipeline and society when we looked at the six notions of bias. Did we miss some other notions? Or are these "untouched" steps never going to introduce any bias?
Next Up
Next, we will consider how the ML pipeline interacts with law and especially anti-discriminatory law.